RAG入門:仕組みとPython×Chromaで作る最小実装

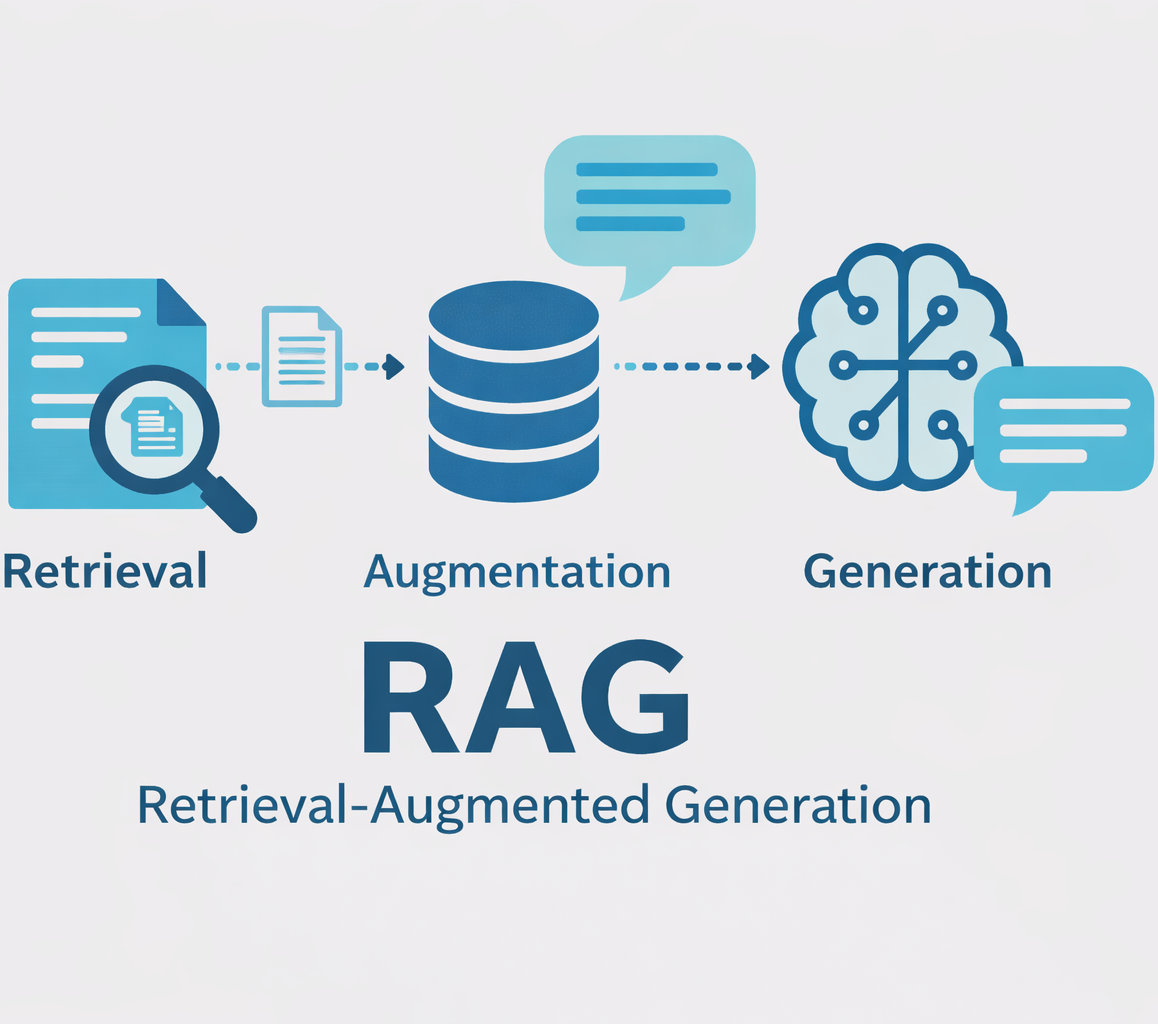
以前の記事で ベクターデータベース についてを書いたが、今回はそれを活用した RAG(Retrieval-Augmented Generation) についてを記載する。
RAG とは何か?
RAG(Retrieval-Augmented Generation)は、日本語で「検索拡張生成」と訳され、外部知識を検索して LLM の回答を強化する技術です。
従来の LLM の課題
ChatGPT などの LLM(Large Language Model)は非常に優秀ですが、以下のような課題があります。
- 知識の鮮度問題: 最新のデータ・情報を知らない
- ハルシネーション(幻覚): もっともらしい嘘をついてしまうことがある
- 専門知識の不足: 固有の情報や専門的な内容は学習していない
- 情報源の不透明性: 回答の根拠が分からない
RAG がこれらをどう解決するか
RAG は以下のような仕組みで課題を解決します。
ユーザーの質問
- 質問に関連する情報を ベクターデータベース から検索
↓- 検索した情報を「コンテキスト」として LLM に渡す
↓- LLM がコンテキストに基づいて回答を生成
↓- 回答 + 情報源の提示
例
- 質問: 「当社の 2024 年第 3 四半期の売上は?」
- 従来の LLM: 「申し訳ございませんが、その情報は持っていません」
- RAG: ベクターデータベース から決算資料を検索 → 「2024 年 Q3 の売上は 150 億円でした。前年比 15%増となっています。(参照: 2024 年 Q3 決算報告書)」
RAG の主な特徴とメリット
- 最新情報への対応
ベクターデータベース に最新の文書を追加するだけで、LLM が最新情報に基づいて回答できます。モデルの再学習は不要です。
- 専門知識・社内情報の活用
例えば以下のようなデータを ベクターデータベース に格納することで、LLM が専門家のように回答できます。
- 社内の議事録、マニュアル、ドキュメント
- 専門的な技術文書、論文
- 顧客データ、製品カタログ
- ハルシネーションの削減
LLM は提供されたコンテキストに基づいて回答するため、事実に基づかない創作的な回答を減らせる傾向があります。
- 透明性と信頼性
回答の根拠となった文書を明示できるため、ユーザーは情報源を確認できます。
- コスト効率
モデルの再学習に比べて以下のコスト利点があります。
- 開発コストが低い
- 更新が容易
- 計算リソースが少なくて済む
RAG のアーキテクチャ
RAG システムは主に以下のコンポーネントで構成されます。
[オフライン処理: データの準備]
- 文書の収集
↓- チャンク分割(文書を適切なサイズに分割)
↓- Embedding(ベクトル化)
↓- ベクターデータベース に保存
[オンライン処理: ユーザーからの質問]
- ユーザーの質問
↓- 質問の Embedding(ベクトル化)
↓- ベクターデータベース で類似文書を検索
↓- 検索結果をコンテキストとして LLM に渡す
↓- LLM が回答を生成
↓- 回答 + 参照元の提示
チャンク分割とは
長い文書をそのまま ベクターデータベース に入れると検索精度が落ちるため、適切なサイズ(通常 100〜500 トークン)に分割します。これをチャンク分割といい、チャンクとは、データを小さな単位に分割したものを指します。
例えば 5000 トークンほどある長い技術文書を以下のようなチャンクに分割するといったような感じになります。
元の文書(5000 トークン)
↓
チャンク 1(300 トークン): イントロダクション
チャンク 2(300 トークン): システム概要
チャンク 3(300 トークン): 技術仕様
...
RAG の種類と発展形
RAG の種類としては主に以下のようなものがあります。
基本的な RAG(Naive RAG)
今回のハンズオンで実装する最もシンプルな形式で、質問 → 検索 → 生成の流れをするものです。
Advanced RAG
以下のような特徴を持つ RAG です。
- クエリ拡張: ユーザーの質問を複数のバリエーションに展開して検索
- リランキング: 検索結果を再スコアリングして最も関連性の高いものを選択
- ハイブリッド検索: ベクトル検索とキーワード検索を組み合わせ
Agentic RAG
LLM が自律的に
- 複数回の検索を実行
- 検索結果の評価と追加検索の判断
- 複数の情報源を統合
するものです。
ハンズオン: RAG システムを構築しよう
それでは、前回の ベクターデータベース の知識を活用して、実用的な RAG システムを構築していきましょう。
前提条件
このハンズオンは、前回のベクターデータベースの記事での環境構築が完了していることを前提としています。
- Python 3.9 以上
- 仮想環境の作成と有効化
- chromadb、openai、python-dotenv のインストール
- OpenAI API キーの設定
まだの方は、前回の記事を参照して環境を整えてください。
プロジェクト構成
今回は以下のような構成でプロジェクトを作成します。
rag-tutorial/
├── venv/ # 仮想環境
├── .env # APIキー
├── documents/ # サンプル文書(新規作成)
│ └── sample_docs.txt
├── data_preparation.py # データ準備スクリプト(新規作成)
├── rag_system.py # RAGシステム本体(新規作成)
└── rag_app.py # 対話型アプリ(新規作成)
ステップ 1: サンプル文書の準備
実際の RAG システムでは社内文書やマニュアルを使いますが、今回はサンプルとして技術文書を用意します。
以下のdocuments/sample_docs.txtを作成しましょう。
=== Python プログラミング言語 ===
Pythonは1991年にGuido van Rossumによって開発されたプログラミング言語です。シンプルで読みやすい構文が特徴で、初心者にも学びやすい言語として知られています。データサイエンス、機械学習、Web開発など幅広い分野で使用されています。Pythonの哲学は「The Zen of Python」として文書化されており、「Simple is better than complex」などの格言が含まれています。
=== JavaScript プログラミング言語 ===
JavaScriptは1995年にBrendan Eichによって開発されたプログラミング言語です。当初はブラウザ上で動作するスクリプト言語として設計されましたが、Node.jsの登場によりサーバーサイドでも広く使われるようになりました。現在ではReact、Vue、Angularなどのフレームワークを用いたフロントエンド開発において中心的な役割を果たしています。
=== 機械学習の基礎 ===
機械学習は人工知能の一分野で、明示的なプログラミングなしにコンピュータがデータから学習する技術です。教師あり学習、教師なし学習、強化学習の3つの主要なカテゴリがあります。教師あり学習では、ラベル付きのデータを使ってモデルを訓練します。代表的な手法には線形回帰、ロジスティック回帰、決定木、ランダムフォレスト、ニューラルネットワークなどがあります。
=== ディープラーニング ===
ディープラーニングは機械学習の一手法で、多層のニューラルネットワークを使用してデータの複雑なパターンを学習します。2012年のImageNetコンペティションでAlexNetが優勝して以来、画像認識、自然言語処理、音声認識などの分野で革命的な進歩をもたらしました。CNN(畳み込みニューラルネットワーク)は画像処理に、RNN(再帰型ニューラルネットワーク)やTransformerは自然言語処理に広く使われています。
=== ベクターデータベース ===
ベクターデータベースは、高次元ベクトルデータを効率的に保存・検索するために設計されたデータベースシステムです。従来のデータベースが完全一致検索や範囲検索を得意とするのに対し、ベクターデータベースは類似度検索に特化しています。生成AIの文脈では、テキストや画像をEmbedding(埋め込み)と呼ばれるベクトルに変換し、意味的に類似したコンテンツを検索するために使用されます。Pinecone、Weaviate、Chroma、Qdrantなどの製品があります。
=== RAG(Retrieval-Augmented Generation) ===
RAGは、大規模言語モデル(LLM)の回答生成能力と情報検索を組み合わせた技術です。ユーザーからの質問に対して、まずベクターデータベースから関連する文書を検索し、その情報をコンテキストとしてLLMに渡すことで、より正確で根拠のある回答を生成します。これにより、LLMの知識カットオフ問題やハルシネーション(幻覚)の問題を軽減し、企業固有の情報や最新の情報に基づいた回答が可能になります。
=== Transformer アーキテクチャ ===
Transformerは2017年に「Attention is All You Need」論文で提案されたニューラルネットワークアーキテクチャです。自己注意機構(Self-Attention)を中核とし、系列データの長距離依存関係を効果的に捉えることができます。BERT、GPT、T5など、現代の多くの大規模言語モデルの基礎となっています。TransformerはRNNの逐次処理の制約を克服し、並列処理が可能なため、大規模なモデルの訓練を実現しました。
=== 自然言語処理(NLP) ===
自然言語処理は、人間の言語をコンピュータで処理・理解・生成する技術分野です。形態素解析、構文解析、意味解析などの基礎技術から、機械翻訳、感情分析、質問応答、文書要約などの応用まで幅広いタスクがあります。近年では、BERT、GPT、T5などの事前学習済み言語モデルの登場により、少量のデータでも高精度なタスク遂行が可能になりました。
ステップ 2: データ準備スクリプトの作成
文書をチャンクに分割して ベクターデータベース に格納するスクリプトdata_preparation.pyを作成します。
(今回はサンプル文書が短いため、セクション単位を 1 チャンクとして扱っています。実務などでは文書が長くなることが多いため、トークン数ベースで一定長+オーバーラップ付きで分割するのが一般的です。)
import chromadb
import os
from dotenv import load_dotenv
import re
from openai import OpenAI
# 環境変数の読み込み
load_dotenv()
client = OpenAI(api_key=os.getenv("OPENAI_API_KEY"))
def load_documents(file_path):
"""
テキストファイルから文書を読み込み、セクションごとに分割
"""
with open(file_path, 'r', encoding='utf-8') as f:
content = f.read()
# デバッグ: ファイル内容の確認
print(f"\nファイル全体の文字数: {len(content)}")
print(f"改行文字の数: {content.count(chr(10))}")
# "===" で区切られたセクションを正規表現で抽出
# パターン: === タイトル === 改行 本文
pattern = r'===\s*([^=]+?)\s*===\s*\n(.*?)(?=\n===|$)'
matches = re.findall(pattern, content, re.DOTALL)
documents = []
metadatas = []
print(f"\n正規表現で{len(matches)}個のセクションを検出")
for i, (title, content_text) in enumerate(matches):
title = title.strip()
content_text = content_text.strip()
if content_text:
documents.append(content_text)
metadatas.append({
'title': title,
'length': len(content_text),
'source': 'sample_docs.txt'
})
print(f" {i+1}. {title} ({len(content_text)}文字)")
# 正規表現でうまくいかない場合の代替方法
if len(documents) == 0:
print("\n正規表現での抽出に失敗しました。代替方法を試します...")
# より単純な分割方法
sections = content.split('===')
for i in range(len(sections)):
section = sections[i].strip()
if not section:
continue
# セクションの最初の行をタイトルとして扱う
lines = section.split('\n')
if len(lines) >= 1:
# 最初の行がタイトル
title = lines[0].strip()
# 残りが本文
content_text = '\n'.join(lines[1:]).strip()
if content_text and len(content_text) > 10: # 最低10文字以上
documents.append(content_text)
metadatas.append({
'title': title,
'length': len(content_text),
'source': 'sample_docs.txt'
})
print(f" {len(documents)}. {title} ({len(content_text)}文字)")
return documents, metadatas
def get_embedding(text):
"""
OpenAI APIを使ってテキストをベクトル化
"""
response = client.embeddings.create(
model="text-embedding-3-small",
input=text
)
return response.data[0].embedding
def prepare_vector_database():
"""
ベクターデータベースを準備し、文書を格納
"""
print("="*60)
print("ベクターデータベース準備スクリプト")
print("="*60)
# ファイルの存在確認
file_path = 'documents/sample_docs.txt'
if not os.path.exists(file_path):
print(f"\nエラー: {file_path} が見つかりません")
print("documentsディレクトリとsample_docs.txtファイルを作成してください")
return
print(f"\n文書ファイルを読み込んでいます: {file_path}")
documents, metadatas = load_documents(file_path)
print(f"\n{'='*60}")
print(f"合計 {len(documents)}個の文書を読み込みました")
print(f"{'='*60}")
if len(documents) == 0:
print("\nエラー: 文書が読み込まれませんでした")
print("\nsample_docs.txtの形式を確認してください:")
print("期待される形式:")
print("=== タイトル1 ===")
print("本文1の内容...")
print("")
print("=== タイトル2 ===")
print("本文2の内容...")
return
print("\nChromaクライアントを初期化しています...")
chroma_client = chromadb.PersistentClient(path="./chroma_db")
# 既存のコレクションがあれば削除
try:
chroma_client.delete_collection(name="tech_knowledge_base")
print("✓ 既存のコレクションを削除しました")
except:
pass
# 新しいコレクションを作成
collection = chroma_client.create_collection(
name="tech_knowledge_base",
metadata={"description": "技術知識ベース"}
)
print("✓ 新しいコレクションを作成しました")
print("\n文書をベクトル化しています...")
embeddings = []
for i, doc in enumerate(documents):
print(f" {i+1}/{len(documents)}: {metadatas[i]['title'][:30]}...")
embedding = get_embedding(doc)
embeddings.append(embedding)
# ベクターデータベースに追加
print("\nベクターデータベースに文書を追加しています...")
ids = [f"doc_{i}" for i in range(len(documents))]
collection.add(
documents=documents,
embeddings=embeddings,
metadatas=metadatas,
ids=ids
)
print(f"\n{'='*60}")
print(f"✓ 完了! {len(documents)}個の文書をベクターデータベースに格納しました")
print(f" 保存場所: ./chroma_db")
print(f"{'='*60}")
# 動作確認
print("\n動作確認: テスト検索を実行...")
test_query = "Pythonについて"
test_query_embedding = get_embedding(test_query) # Embeddingを生成
test_results = collection.query(
query_embeddings=[test_query_embedding], # query_textsではなくquery_embeddings
n_results=1
)
if test_results.get("documents") and test_results["documents"][0]:
print(f"✓ テスト検索成功")
print(f" 検索結果: {test_results['metadatas'][0][0]['title']}")
return collection
if __name__ == "__main__":
prepare_vector_database()
このスクリプトの重要ポイント
- PersistentClient: データをディスクに永続化する Chroma クライアント
- セクション分割:
===で区切られた各トピックを 1 つの文書として扱う - メタデータ: タイトル、文字数、出典を記録
- Embedding: OpenAI の API で各文書をベクトル化
実行方法
python data_preparation.py
実行結果
============================================================
ベクターデータベース準備スクリプト
============================================================
文書ファイルを読み込んでいます: documents/sample_docs.txt
ファイル全体の文字数: 1822
改行文字の数: 22
正規表現で8個のセクションを検出
1. Python プログラミング言語 (212文字)
2. JavaScript プログラミング言語 (182文字)
3. 機械学習の基礎 (173文字)
4. ディープラーニング (208文字)
5. ベクターデータベース (239文字)
6. RAG(Retrieval-Augmented Generation) (198文字)
7. Transformer アーキテクチャ (227文字)
8. 自然言語処理(NLP) (165文字)
============================================================
合計 8個の文書を読み込みました
============================================================
Chromaクライアントを初期化しています...
✓ 既存のコレクションを削除しました
✓ 新しいコレクションを作成しました
文書をベクトル化しています...
1/8: Python プログラミング言語...
2/8: JavaScript プログラミング言語...
3/8: 機械学習の基礎...
4/8: ディープラーニング...
5/8: ベクターデータベース...
6/8: RAG(Retrieval-Augmented Genera...
7/8: Transformer アーキテクチャ...
8/8: 自然言語処理(NLP)...
ベクターデータベースに文書を追加しています...
============================================================
✓ 完了! 8個の文書をベクターデータベースに格納しました
保存場所: ./chroma_db
============================================================
動作確認: テスト検索を実行...
✓ テスト検索成功
検索結果: Python プログラミング言語
実行するとchroma_dbディレクトリが作成され、ベクトル化された文書が保存されます。
ステップ 3: RAG システム本体の実装
次に、質問に対して RAG で回答するシステムrag_system.pyを作成します。
import chromadb
import os
from dotenv import load_dotenv
from typing import List, Dict
from openai import OpenAI
# 環境変数の読み込み
load_dotenv()
client = OpenAI(api_key=os.getenv("OPENAI_API_KEY"))
class RAGSystem:
"""
RAG(Retrieval-Augmented Generation)システム
"""
def __init__(self, collection_name: str = "tech_knowledge_base"):
"""
RAGシステムを初期化
Args:
collection_name: 使用するChromaコレクション名
"""
self.chroma_client = chromadb.PersistentClient(path="./chroma_db")
self.collection = self.chroma_client.get_collection(name=collection_name)
print(f"✓ コレクション '{collection_name}' を読み込みました")
def get_embedding(self, text: str) -> List[float]:
"""
テキストをベクトル化
"""
response = client.embeddings.create(
model="text-embedding-3-small",
input=text
)
return response.data[0].embedding
def retrieve(self, query: str, top_k: int = 3) -> Dict:
"""
質問に関連する文書を検索
Args:
query: ユーザーの質問
top_k: 取得する文書数
Returns:
検索結果(文書、メタデータ、スコア)
"""
# 質問をベクトル化
query_embedding = self.get_embedding(query)
# ベクターデータベースから類似文書を検索
results = self.collection.query(
query_embeddings=[query_embedding],
n_results=top_k
)
return results
def generate_answer(self, query: str, context: str, model: str = "gpt-4o-mini") -> str:
"""
コンテキストに基づいて回答を生成
Args:
query: ユーザーの質問
context: 検索で取得したコンテキスト
model: 使用するGPTモデル
Returns:
生成された回答
"""
# プロンプトの構築
system_prompt = """あなたは親切で知識豊富なAIアシスタントです。
提供されたコンテキストに基づいて、ユーザーの質問に正確に回答してください。
コンテキストに情報がない場合は、その旨を正直に伝えてください。
回答は分かりやすく、簡潔にまとめてください。"""
user_prompt = f"""以下のコンテキストを参考にして、質問に答えてください。
【コンテキスト】
{context}
【質問】
{query}
【回答】"""
# OpenAI APIで回答を生成
response = client.chat.completions.create(
model=model,
messages=[
{"role": "system", "content": system_prompt},
{"role": "user", "content": user_prompt}
],
temperature=0.3, # 低めに設定して事実ベースの回答を促す
max_tokens=500
)
return response.choices[0].message.content
def query(self, question: str, top_k: int = 3, verbose: bool = True) -> Dict:
"""
RAGパイプライン全体を実行
Args:
question: ユーザーの質問
top_k: 検索する文書数
verbose: 詳細情報を表示するか
Returns:
回答と関連情報
"""
if verbose:
print(f"\n{'='*60}")
print(f"質問: {question}")
print(f"{'='*60}")
# 1. 関連文書を検索
if verbose:
print("\n[ステップ1: 関連文書の検索]")
search_results = self.retrieve(question, top_k)
if verbose:
print(f"✓ {len(search_results['documents'][0])}件の関連文書を取得しました")
for i, (doc, meta) in enumerate(zip(
search_results['documents'][0],
search_results['metadatas'][0]
), 1):
print(f"\n 文書{i}: {meta['title']}")
print(f" 内容: {doc[:100]}...")
# 2. コンテキストの構築
context = "\n\n".join([
f"【{meta['title']}】\n{doc}"
for doc, meta in zip(
search_results['documents'][0],
search_results['metadatas'][0]
)
])
# 3. LLMで回答を生成
if verbose:
print("\n[ステップ2: 回答の生成]")
answer = self.generate_answer(question, context)
if verbose:
print(f"\n{'='*60}")
print(f"回答:\n{answer}")
print(f"{'='*60}")
print("\n[参照した情報源]")
for i, meta in enumerate(search_results['metadatas'][0], 1):
print(f" {i}. {meta['title']} ({meta['source']})")
return {
'answer': answer,
'sources': search_results['documents'][0],
'metadata': search_results['metadatas'][0]
}
# テスト実行
if __name__ == "__main__":
# RAGシステムを初期化
rag = RAGSystem()
# テスト質問
test_questions = [
"Pythonの特徴を教えてください",
"機械学習とディープラーニングの違いは何ですか?",
"RAGとは何ですか?どのように動作しますか?"
]
for question in test_questions:
result = rag.query(question, top_k=2)
print("\n" + "="*60 + "\n")
このスクリプトの重要ポイント
- RAGSystem クラス: 再利用可能な RAG システム
- retrieve(): ベクターデータベース から関連文書を検索
- generate_answer(): コンテキストを使って LLM で回答生成
- query(): 検索 → 生成のパイプライン全体を実行
- verbose: 処理過程を表示するオプション
実行方法
python rag_system.py
実行結果(例)
今回はサンプル文書が少ないため、上位 k 件の中に直接関係が薄い文書が混ざることがありますが、実務ではデータ量・チャンク設計・リランキング等で改善します。
✓ コレクション 'tech_knowledge_base' を読み込みました
============================================================
質問: Pythonの特徴を教えてください
============================================================
[ステップ1: 関連文書の検索]
✓ 2件の関連文書を取得しました
文書1: Python プログラミング言語
内容: Pythonは1991年にGuido van Rossumによって開発されたプログラミング言語です。シンプルで読みやすい構文が特徴で、初心者にも学びやすい言語として知られています。データサイエンス、機...
文書2: 機械学習の基礎
内容: 機械学習は人工知能の一分野で、明示的なプログラミングなしにコンピュータがデータから学習する技術です。教師あり学習、教師なし学習、強化学習の3つの主要なカテゴリがあります。教師あり学習では、ラベル付きの...
[ステップ2: 回答の生成]
============================================================
回答:
Pythonの特徴は以下の通りです:
1. **シンプルで読みやすい構文**:初心者でも理解しやすく、コードが直感的に書ける。
2. **多用途性**:データサイエンス、機械学習、Web開発など、さまざまな分野で使用される。
3. **豊富なライブラリ**:多くのライブラリやフレームワークがあり、特定のタスクを簡単に実行できる。
4. **オープンソース**:無料で使用でき、コミュニティが活発であるため、サポートやリソースが豊富。
5. **プラットフォーム独立性**:Windows、macOS、Linuxなど、さまざまなプラットフォームで動作する。
これらの特徴により、Pythonは広く利用されているプログラミング言語となっています。
============================================================
[参照した情報源]
1. Python プログラミング言語 (sample_docs.txt)
2. 機械学習の基礎 (sample_docs.txt)
============================================================
============================================================
質問: 機械学習とディープラーニングの違いは何ですか?
============================================================
[ステップ1: 関連文書の検索]
✓ 2件の関連文書を取得しました
文書1: ディープラーニング
内容: ディープラーニングは機械学習の一手法で、多層のニューラルネットワークを使用してデータの複雑なパターンを学習します。2012年のImageNetコンペティションでAlexNetが優勝して以来、画像認識、...
文書2: 機械学習の基礎
内容: 機械学習は人工知能の一分野で、明示的なプログラミングなしにコンピュータがデータから学習する技術です。教師あり学習、教師なし学習、強化学習の3つの主要なカテゴリがあります。教師あり学習では、ラベル付きの...
[ステップ2: 回答の生成]
============================================================
回答:
機械学習とディープラーニングの違いは、主に以下の点にあります。
1. **手法の複雑さ**: 機械学習は、データから学習するためのさまざまな手法を含む広い分野であり、線形回帰や決定木などの比較的シンプルなアルゴリズムを使用します。一方、ディープラーニングはその一部であり、多層のニューラルネットワークを使用して、より複雑なパターンを学習します。
2. **データの処理能力**: ディープラーニングは大量のデータを扱うのに適しており、特に画像や音声、自然言語などの非構造化データの処理に優れています。機械学習の手法は、通常、より少ないデータでも効果的に機能します。
3. **特徴抽出**: 機械学習では、特徴量を手動で選択する必要があることが多いですが、ディープラーニングは自動的に特徴を抽出する能力があります。
このように、ディープラーニングは機械学習の一部であり、特に複雑な問題に対して強力なアプローチを提供します。
============================================================
[参照した情報源]
1. ディープラーニング (sample_docs.txt)
2. 機械学習の基礎 (sample_docs.txt)
============================================================
============================================================
質問: RAGとは何ですか?どのように動作しますか?
============================================================
[ステップ1: 関連文書の検索]
✓ 2件の関連文書を取得しました
文書1: RAG(Retrieval-Augmented Generation)
内容: RAGは、大規模言語モデル(LLM)の回答生成能力と情報検索を組み合わせた技術です。ユーザーからの質問に対して、まずベクターデータベースから関連する文書を検索し、その情報をコンテキストとして...
文書2: JavaScript プログラミング言語
内容: JavaScriptは1995年にBrendan Eichによって開発されたプログラミング言語です。当初はブラウザ上で動作するスクリプト言語として設計されましたが、Node.jsの登場によりサーバーサ...
[ステップ2: 回答の生成]
============================================================
回答:
RAG(Retrieval-Augmented Generation)とは、大規模言語モデル(LLM)の回答生成能力と情報検索を組み合わせた技術です。この技術は、ユーザーからの質問に対してまず関連する文書をベクターデータベースから検索し、その情報をコンテキストとしてLLMに渡します。これにより、より正確で根拠のある回答を生成することができます。
具体的には、RAGは以下のように動作します:
1. ユーザーの質問を受け取る。
2. ベクターデータベースから関連する文書を検索する。
3. 検索した情報をLLMに渡し、回答を生成する。
このプロセスによって、LLMの知識カットオフ問題やハルシネーション(幻覚)の問題を軽減し、企業固有の情報や最新の情報に基づいた回答が可能になります。
============================================================
[参照した情報源]
1. RAG(Retrieval-Augmented Generation) (sample_docs.txt)
2. JavaScript プログラミング言語 (sample_docs.txt)
============================================================
本番運用で押さえるべきポイント
もし実際に RAG システムを運用する際は、以下の点に注意しましょう。
- データの品質管理: 情報の正確性と定期的な更新
- セキュリティ: メタデータによるアクセス制御と個人情報保護
- コスト管理: キャッシングの活用と API 呼び出しの最適化
- ユーザーフィードバック: 評価機能を実装して継続的に改善
RAG は社内データや最新情報を扱う用途で、特に採用されやすい重要技術です。まずは小さく始めて、ユーザーの反応を見ながら改善していくアプローチが成功の鍵となります。
実際に手を動かして、自分のドメインに合わせた RAG システムを構築してみてください。