Langfuseを使ってみる

前回の記事では、AWS Lambda から Amazon Bedrock の基盤モデル(Nova)を呼び出す最小構成を Terraform で構築しました。動くものはできましたが、運用フェーズに入ると次のような疑問が必ず出てきます。
- どんなプロンプトが投げられて、モデルは何を返したのか?
- 1 リクエストあたり何トークン消費していて、コストはいくらなのか?
- レイテンシは?エラーはどのくらいの頻度で起きているのか?
これらに答えるのが LLM オブザーバビリティ です。本記事では、前回の構成に Langfuse1 を導入して、Bedrock の呼び出しを「見える化」していきます。
Langfuse とは?
Langfuse は、LLM アプリケーション向けのオープンソースのオブザーバビリティ・プラットフォームです。LLM の呼び出しを「トレース」として記録し、入出力・トークン・コスト・レイテンシを 1 つの画面で確認できます。
なぜ LLM に専用のオブザーバビリティが必要なのか
CloudWatch Logs でも print した内容は追えます。ですが LLM の運用では、ログを眺めるだけでは扱いづらい固有の事情があります。
| 課題 | 内容 |
|---|---|
| 入出力が構造化しづらい | プロンプトとレスポンスは長文の自然言語。ログに流すと埋もれてしまい、後から追うのが大変。 |
| トークン・コスト管理 | モデル・リージョンごとに単価が異なり、トークン消費を集計しないとコストが読めない。 |
| 多段の処理を追いたい | RAG やエージェントでは 1 リクエストが複数のモデル呼び出しに分かれる。これを 1 本の線で見たい。 |
| 品質評価 | 「良い応答だったか」を後から評価・スコアリングして改善サイクルを回したい。 |
Langfuse はこれらを トレース/オブザベーション という単位で構造的に記録してくれます。
主な特徴
| 特徴 | 説明 |
|---|---|
| トレーシング | LLM 呼び出しの入出力・トークン・レイテンシを自動記録。ネストした処理もツリー構造で可視化できる。 |
| コスト・トークン可視化 | モデルごとのトークン消費とコストを集計。カスタム単価も設定可能。 |
| マルチ SDK / フレームワーク | Python / JS SDK のほか、LangChain・LlamaIndex・LiteLLM など主要フレームワークと連携できる。 |
| 評価機能 | LLM-as-a-judge やヒューマンアノテーションでトレースにスコアを付与できる。 |
| OSS / マネージドの両対応 | セルフホストも、Langfuse Cloud(マネージド)も選べる。 |
ホスティングについて: 本記事では手軽に始められる Langfuse Cloud を使います。Langfuse Cloud には EU・US に加えて 日本(jp.cloud.langfuse.com) のデータリージョンがあるため、日本国内のプロジェクトでも扱いやすくなっています。セルフホストしたい場合は公式の Self-hosting ガイド を参照してください。
ハンズオン構成
前回の最小構成(Lambda → Bedrock Converse API)はそのまま活かし、そこに Langfuse による計装を足します。
計装の方式について
Langfuse から Bedrock を計装する方法はいくつかあります(LangChain などのフレームワーク経由、LiteLLM のようなプロキシ経由、SDK のデコレータで直接ラップする方式)。今回は boto3 だけで完結し、依存も最小限で済む 「Langfuse Python SDK の @observe デコレータで Converse 呼び出しをラップする」方式を採用します。Bedrock のモデルしか使わないシンプルな構成では、これが一番素直です。
構成要素(前回からの差分)
- Lambda Layer(追加):
langfuseパッケージを同梱する Lambda Layer - 環境変数(追加):Langfuse の接続情報(公開鍵・秘密鍵・ホスト)
- Lambda コード(変更):Converse 呼び出しを
@observeでラップし、トレースを送信
キー管理の注意: 本ハンズオンでは手順を簡潔にするため Langfuse のキーを Lambda の環境変数に直接設定します。実運用では AWS Secrets Manager や SSM Parameter Store に保管し、実行時に取得する形を推奨します。
処理の流れ(どう変わるか)
- ユーザーが Lambda 関数を
invokeする(前回と同じ) - Lambda が Bedrock の Converse API を呼び出す。このとき呼び出しが
@observeでラップされ、入力・モデル ID・推論パラメータが記録される - レスポンスからトークン使用量・出力テキストを抽出し、Langfuse のトレースに付与する
- Lambda の終了前に
flush()を呼び、バッファされたトレースを Langfuse へ確実に送信する - Langfuse の UI でトレース・トークン・コスト・レイテンシを確認する
Lambda 固有の落とし穴: Langfuse SDK はトレースをバックグラウンドでバッチ送信します。Lambda は処理が終わると実行環境が凍結(freeze)されるため、ハンドラーの最後で必ず
langfuse.flush()を呼ばないと、トレースが送信されないまま終わる ことがあります。ここが今回の一番の勘所です。
ゴール: 前回の Lambda 関数に Langfuse を組み込み、Bedrock の呼び出しを 1 件のトレースとして Langfuse Cloud に可視化する。
前提条件
前回の前提に加えて、以下を準備してください。
- 前回のハンズオン環境(Lambda + Bedrock + Terraform)が動く状態であること
- Langfuse Cloud アカウント(cloud.langfuse.com で無料で作成可能)
- Langfuse でプロジェクトを 1 つ作成し、Public Key / Secret Key を取得済みであること
Langfuse のキー取得手順
- Langfuse Cloud にサインインする(日本リージョンを使う場合は
https://jp.cloud.langfuse.com) - 新規プロジェクトを作成する
- プロジェクトの Settings → API Keys から Create new API keys を実行
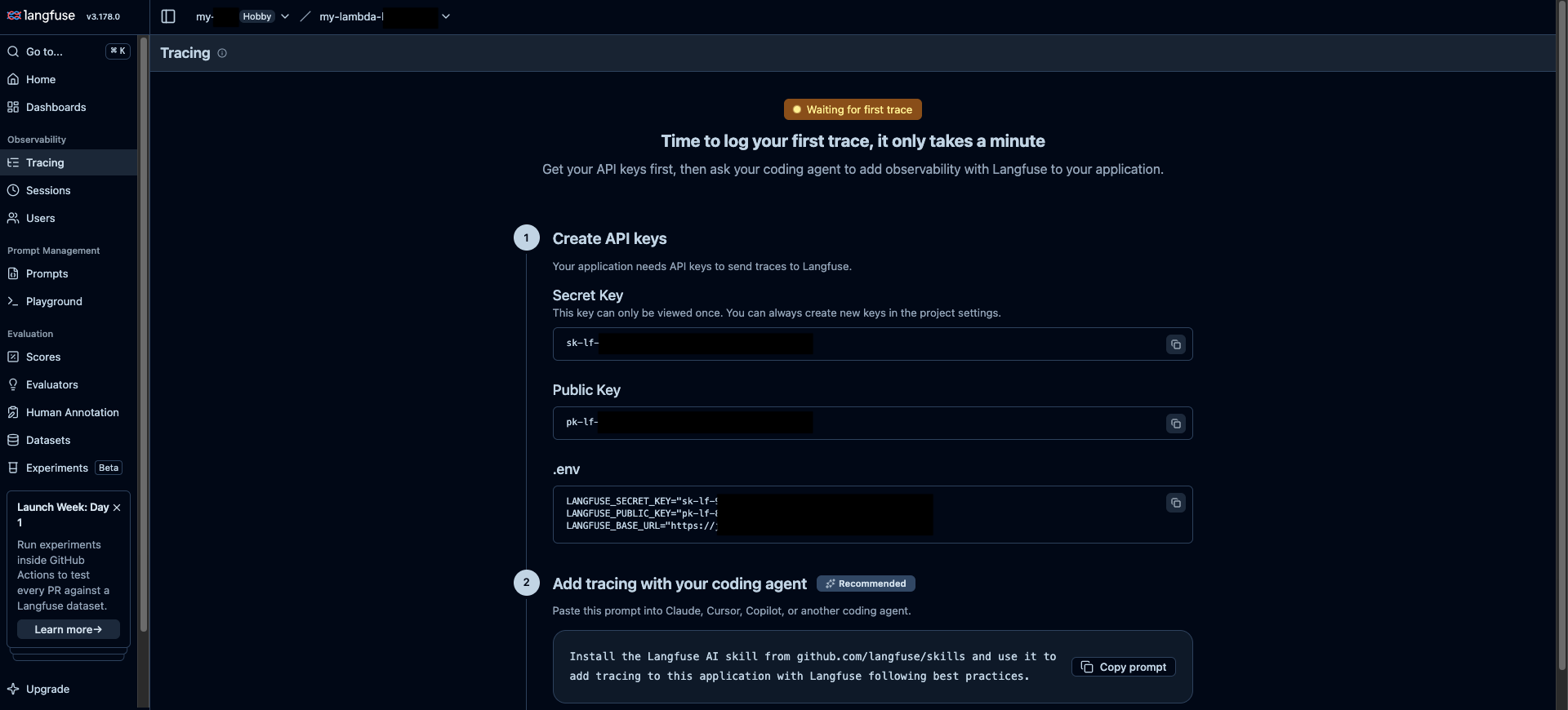
- 表示される Public Key(
pk-lf-...) と Secret Key(sk-lf-...) を控える(Secret Key は再表示されないので注意)
ディレクトリ構成
前回の構成に Layer 用のディレクトリを追加します。
bedrock-handson/
├── main.tf # メインリソース定義(Layer 追加)
├── variables.tf # 変数定義(Langfuse 用変数を追加)
├── outputs.tf # 出力定義
├── provider.tf # プロバイダー設定
├── iam.tf # IAM ロール・ポリシー(変更なし)
├── lambda_src/
│ └── index.py # Lambda ハンドラー(Langfuse 計装を追加)
├── layer/ # Lambda Layer 用(新規)
│ └── requirements.txt # langfuse を記載
└── terraform.tfvars # 変数値(Langfuse のキーを設定)
Terraform コード
前回からの変更点を中心に記載します。provider.tf と iam.tf は前回のままで動きます。
- variables.tf(Langfuse 用の変数を追加)
variable "aws_region" {
description = "AWS リージョン"
type = string
default = "us-east-1"
}
variable "bedrock_model_id" {
description = "Bedrock で使用する基盤モデルの ID"
type = string
default = "amazon.nova-lite-v1:0"
}
variable "lambda_function_name" {
description = "Lambda 関数名"
type = string
default = "bedrock-invoke-demo"
}
# --- ここから追加 ---
variable "langfuse_public_key" {
description = "Langfuse Public Key (pk-lf-...)"
type = string
sensitive = true
}
variable "langfuse_secret_key" {
description = "Langfuse Secret Key (sk-lf-...)"
type = string
sensitive = true
}
variable "langfuse_host" {
description = "Langfuse のホスト URL"
type = string
# 日本: https://jp.cloud.langfuse.com
# EU: https://cloud.langfuse.com
# US: https://us.cloud.langfuse.com
default = "https://jp.cloud.langfuse.com"
}
- layer/requirements.txt
langfuse
- main.tf(Lambda Layer の追加と、Lambda 関数への適用・環境変数追加)
# -----------------------------------------------
# Lambda 関数用ビルドディレクトリの作成
# -----------------------------------------------
resource "null_resource" "create_build_dir" {
provisioner "local-exec" {
command = "mkdir -p ${path.module}/.build"
}
}
# -----------------------------------------------
# Lambda Layer 用の依存パッケージをビルド
# pip install で python/ 配下に langfuse を展開する
# (Lambda Layer は python/ 以下が import パスになる)
# -----------------------------------------------
resource "null_resource" "build_layer" {
# requirements.txt が変わったら再ビルド
triggers = {
requirements = filemd5("${path.module}/layer/requirements.txt")
}
provisioner "local-exec" {
command = <<-EOT
rm -rf ${path.module}/.build/layer
mkdir -p ${path.module}/.build/layer/python
pip install -r ${path.module}/layer/requirements.txt \
--target ${path.module}/.build/layer/python \
--python-version 3.12 \
--only-binary=:all: \
--platform manylinux2014_x86_64
EOT
}
depends_on = [null_resource.create_build_dir]
}
# Layer の ZIP 化
data "archive_file" "layer_zip" {
type = "zip"
source_dir = "${path.module}/.build/layer"
output_path = "${path.module}/.build/layer.zip"
depends_on = [null_resource.build_layer]
}
resource "aws_lambda_layer_version" "langfuse_layer" {
layer_name = "langfuse-deps"
filename = data.archive_file.layer_zip.output_path
source_code_hash = data.archive_file.layer_zip.output_base64sha256
compatible_runtimes = ["python3.12"]
}
# -----------------------------------------------
# Lambda 関数用 ZIP パッケージ
# -----------------------------------------------
data "archive_file" "lambda_zip" {
type = "zip"
source_dir = "${path.module}/lambda_src"
output_path = "${path.module}/.build/lambda.zip"
depends_on = [null_resource.create_build_dir]
}
# -----------------------------------------------
# CloudWatch Logs ロググループ
# -----------------------------------------------
resource "aws_cloudwatch_log_group" "lambda_log" {
name = "/aws/lambda/${var.lambda_function_name}"
retention_in_days = 14
}
# -----------------------------------------------
# Lambda 関数(Layer と Langfuse 用環境変数を追加)
# -----------------------------------------------
resource "aws_lambda_function" "bedrock_demo" {
function_name = var.lambda_function_name
role = aws_iam_role.lambda_bedrock_role.arn
handler = "index.handler"
runtime = "python3.12"
timeout = 60
memory_size = 256
filename = data.archive_file.lambda_zip.output_path
source_code_hash = data.archive_file.lambda_zip.output_base64sha256
# Langfuse の依存を Layer として適用
layers = [aws_lambda_layer_version.langfuse_layer.arn]
environment {
variables = {
BEDROCK_MODEL_ID = var.bedrock_model_id
LANGFUSE_PUBLIC_KEY = var.langfuse_public_key
LANGFUSE_SECRET_KEY = var.langfuse_secret_key
LANGFUSE_HOST = var.langfuse_host
}
}
depends_on = [
aws_iam_role_policy_attachment.lambda_basic_execution,
aws_cloudwatch_log_group.lambda_log,
]
}
- terraform.tfvars(キーを設定。Git にコミットしないこと)
langfuse_public_key = "pk-lf-xxxxxxxxxxxxxxxx"
langfuse_secret_key = "sk-lf-xxxxxxxxxxxxxxxx"
langfuse_host = "https://jp.cloud.langfuse.com"
.gitignoreに追加推奨:terraform.tfvarsと.build/はリポジトリに含めないようにしておきましょう。
- lambda_src/index.py(Langfuse 計装を追加)
import json
import os
import boto3
from botocore.exceptions import ClientError
from langfuse import observe, get_client
# Bedrock Runtime クライアント
bedrock_runtime = boto3.client(
"bedrock-runtime",
region_name=os.environ["AWS_REGION"],
)
# Langfuse クライアント
# LANGFUSE_PUBLIC_KEY / LANGFUSE_SECRET_KEY / LANGFUSE_HOST を
# 環境変数から自動的に読み込む
langfuse = get_client()
@observe(as_type="generation", name="Bedrock Converse")
def wrapped_bedrock_converse(**kwargs):
"""Bedrock Converse 呼び出しを Langfuse のトレースとして記録する"""
# 1. 入力・モデルメタデータをトレースに記録
kwargs_clone = kwargs.copy()
input_messages = kwargs_clone.pop("messages", None)
model_id = kwargs_clone.pop("modelId", None)
model_parameters = {
**kwargs_clone.pop("inferenceConfig", {}),
**kwargs_clone.pop("additionalModelRequestFields", {}),
}
langfuse.update_current_generation(
input=input_messages,
model=model_id,
model_parameters=model_parameters,
metadata=kwargs_clone,
)
# 2. モデル呼び出し(エラーもトレースに残す)
try:
response = bedrock_runtime.converse(**kwargs)
except (ClientError, Exception) as e:
error_message = f"ERROR: Can't invoke '{model_id}'. Reason: {e}"
langfuse.update_current_generation(
level="ERROR",
status_message=error_message,
)
raise
# 3. 出力テキストとトークン使用量を記録
output_text = response["output"]["message"]["content"][0]["text"]
langfuse.update_current_generation(
output=output_text,
usage_details={
"input": response["usage"]["inputTokens"],
"output": response["usage"]["outputTokens"],
"total": response["usage"]["totalTokens"],
},
metadata={"ResponseMetadata": response["ResponseMetadata"]},
)
return output_text
@observe(name="bedrock-invoke-demo")
def handler(event, context):
user_message = event.get(
"message",
"こんにちは。AWS Lambda から Bedrock を呼んでいます。",
)
model_id = os.environ["BEDROCK_MODEL_ID"]
try:
reply = wrapped_bedrock_converse(
modelId=model_id,
messages=[
{
"role": "user",
"content": [{"text": user_message}],
}
],
inferenceConfig={
"maxTokens": 300,
"temperature": 0.7,
},
)
return {
"statusCode": 200,
"body": json.dumps({"reply": reply}, ensure_ascii=False),
}
finally:
# 重要:Lambda が凍結される前にトレースを確実に送信する
langfuse.flush()
index.py のポイントを整理します。
get_client()は環境変数(LANGFUSE_PUBLIC_KEYなど)から接続情報を自動で読み込むため、コード中にキーを直書きする必要がありません。handler自体も@observeでラップすることで、リクエスト全体が 1 本の トレース になり、その中に Bedrock 呼び出しが オブザベーション(generation) としてネストされます。finally句のlangfuse.flush()が今回の肝です。Lambda は応答を返した直後に実行環境が凍結されるため、明示的に flush しないとトレースが送信されないまま失われる可能性があります。
デプロイ手順
- 初期化 & プラン
cd bedrock-handson
terraform init
terraform plan
Layer のビルドで
pip installがローカル実行されます。手元の Python が 3.12 でない場合でも、--python-versionと--platformを指定しているため Lambda 用のバイナリが取得されます。pip のバージョンが古いとこのオプションが効かないことがあるので、その際はpip install --upgrade pipを実行してください。
- デプロイ
terraform apply
yes を入力して適用します。
- 動作確認
前回と同じく AWS CLI で Lambda を呼び出します。
aws lambda invoke \
--function-name bedrock-invoke-demo \
--cli-binary-format raw-in-base64-out \
--payload '{"message": "Langfuse の良いところを3つ教えて"}' \
response.json
cat response.json | jq .body -r | jq .
期待される出力例:
{
"reply": "Langfuse の良いところを3つ挙げます。1つ目は..."
}
レスポンス自体は前回と変わりません。違いは Langfuse 側にトレースが記録されている ことです。
Langfuse でトレースを確認する
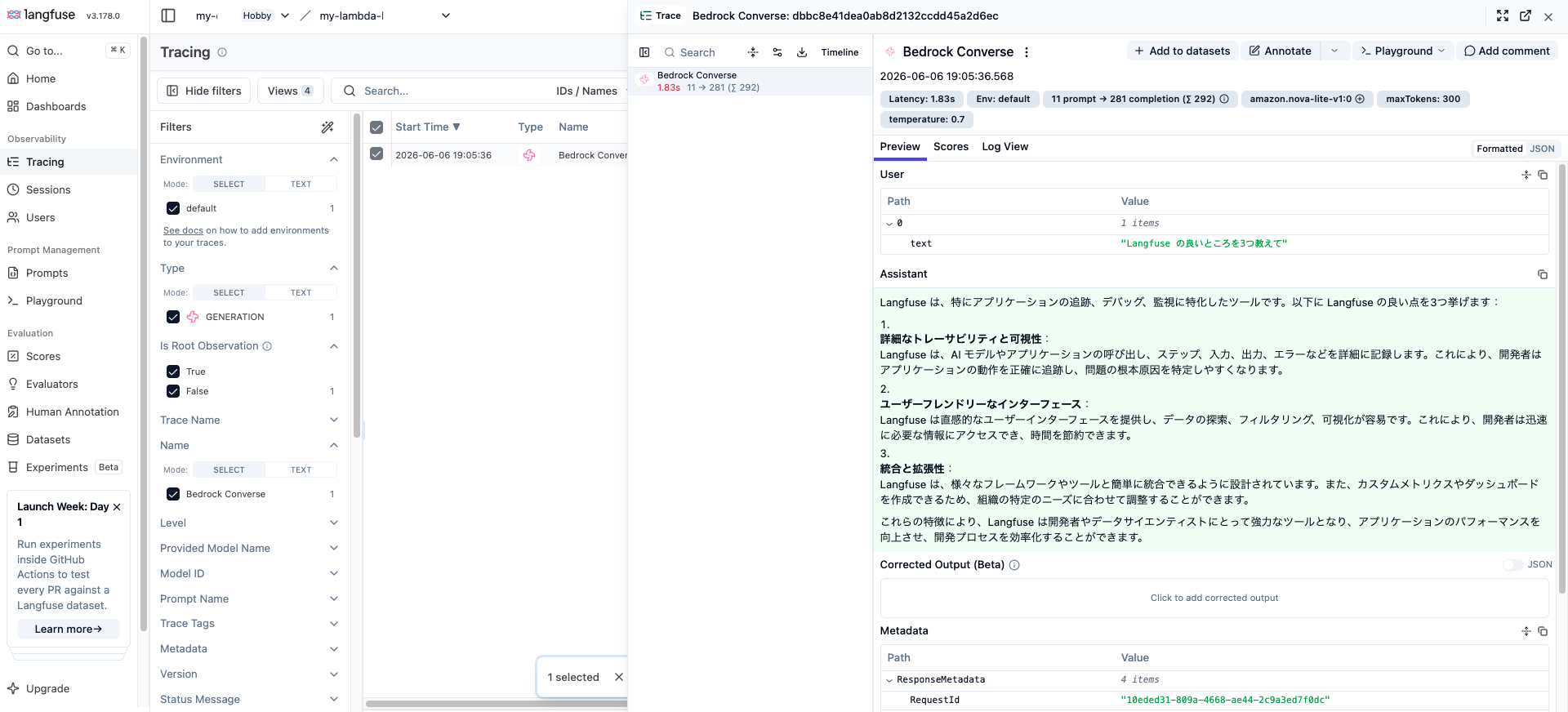
Langfuse Cloud にログインし、対象プロジェクトの Tracing → Traces を開きます。先ほどの呼び出しが 1 件のトレースとして表示されているはずです。トレースをクリックすると、以下が確認できます。
| 確認できる項目 | 内容 |
|---|---|
| Input / Output | Lambda に渡したメッセージと、モデルが返したテキスト |
| Model | 使用したモデル ID(例:amazon.nova-lite-v1:0) |
| Usage | 入力・出力・合計トークン数 |
| Latency | 呼び出しにかかった時間 |
| Metadata | 推論パラメータや ResponseMetadata など |
数回呼び出すと、ダッシュボードでトークン消費やレイテンシの推移も見えるようになります。
コスト表示について
Nova のように Langfuse 側に標準の単価情報がないモデルでは、コストが表示されないことがあります。その場合は Langfuse の Settings → Models からモデル名にマッチする カスタム単価(input / output の 1,000 トークンあたり料金) を登録すると、トレースにコストが自動計算されて表示されるようになります。実際の単価は Bedrock の公式料金ページ で確認してください。
つまずきやすいポイント
| 症状 | 原因と対処 |
|---|---|
| トレースが UI に出てこない | flush() 漏れが最有力。handler の finally で langfuse.flush() を呼んでいるか確認する。 |
No module named 'langfuse' |
Layer のビルドに失敗している。.build/layer/python 配下に langfuse が展開されているか、Layer が Lambda に紐付いているか確認。 |
| 認証エラー(401 など) | Public / Secret Key やホスト URL の取り違え。特にデータリージョン(jp / eu / us)とキーの発行元が一致しているか確認。 |
| コストが 0 のまま | 使用モデルの単価が未登録。Langfuse の Models 設定でカスタム単価を登録する。 |
コールドスタートについて:
get_client()をハンドラー外(モジュールトップ)で初期化しているため、ウォームスタート時は再利用されます。flush はリクエストごとに行うため、トレースの取りこぼしは防げます。
まとめ
前回構築した Bedrock × Lambda の最小構成に Langfuse を組み込み、LLM 呼び出しをトレースとして可視化しました。ポイントは次の 3 つです。
@observeデコレータで Converse 呼び出しをラップするだけで、入出力・トークン・レイテンシが自動記録される- 依存は Lambda Layer に逃がし、コードは boto3 + langfuse だけのシンプルな構成を保てる
- Lambda 特有の事情として、ハンドラー終了前の
flush()が必須
可観測性が手に入ると、次は「品質を測って改善する」フェーズに進めます。応用として以下も試してみてください。
| ステップ | 内容 |
|---|---|
| スコアリング | LLM-as-a-judge やヒューマンアノテーションでトレースに品質スコアを付与する |
| プロンプト管理 | Langfuse Prompt Management でプロンプトをバージョン管理し、A/B 比較する |
| セッション集約 | session_id を付けて、マルチターン会話を 1 セッションとして可視化する |
| セキュアなキー管理 | キーを Secrets Manager / SSM に移し、Lambda 実行時に取得する |